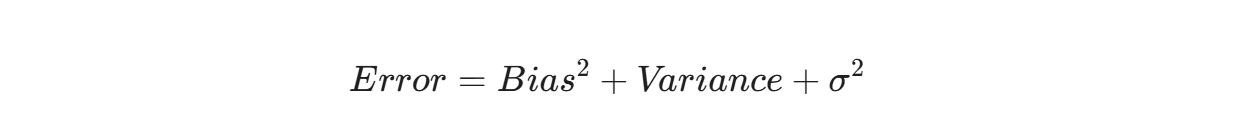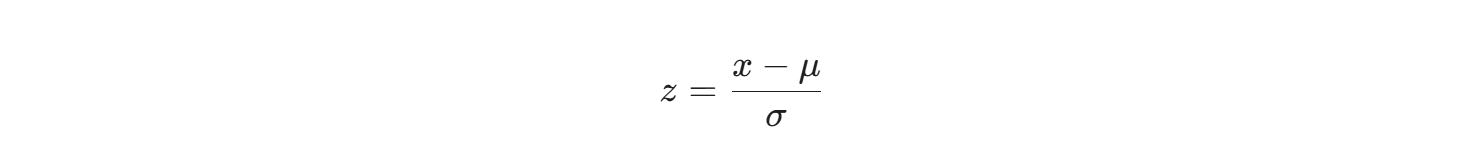- Tham gia
- 19/9/2024
- Bài viết
- 118
Sự bùng nổ của các nền tảng Học máy tự động (AutoML) và các mô hình AI tạo sinh mã nguồn trong những năm gần đây đang tạo ra một làn sóng hoài nghi lớn trong giới công nghệ: Phải chăng kỷ nguyên của các Nhà khoa học dữ liệu (Data Scientists) đang đi đến hồi kết khi máy tính đã có thể tự động viết code và tự động hóa toàn bộ việc tối ưu hóa thuật toán?
Thực tế lại chứng minh điều hoàn toàn ngược lại. Khi rào cản kỹ thuật về lập trình được hạ thấp bởi các công cụ kéo thả tự động, sự phân cấp năng lực giữa các kỹ sư dữ liệu không nằm ở tốc độ gõ code mà nằm ở độ sâu của Tư duy Thống kê.
Tuy nhiên, thuật toán AutoML vận hành thuần túy dựa trên các phép toán số học mà không hề hiểu về ngữ cảnh và bản chất của dữ liệu. Điều này dẫn đến những thảm họa về mặt mô hình hóa mà chỉ có tư duy thống kê của con người mới có thể phát hiện:
Tư duy thống kê giúp nhà phân tích hiểu rõ bản chất của mối quan hệ đánh đổi giữa Bias và Variance thông qua phương trình sai số tổng quát:

Trong đó, $\sigma^2$ là sai số ngẫu nhiên không thể giảm thiểu của dữ liệu. Việc mù quáng tối ưu hóa thuật toán bằng công cụ tự động mà không hiểu cơ chế phân phối xác suất kiểm thử sẽ chỉ làm tăng hệ số Variance và khiến mô hình mất đi khả năng tổng quát hóa (generalization).
Hãy lấy ví dụ về bài toán chấm điểm tín dụng trong ngân hàng. Dữ liệu thô chỉ bao gồm thông tin: Số dư tài khoản hiện tại và Lịch sử thu nhập hằng tháng. AutoML sẽ chỉ trực tiếp đưa hai biến số này vào mô hình.
Nhưng một Data Scientist thực thụ sẽ sử dụng toán thống kê để chuẩn hóa dữ liệu theo phân phối chuẩn:
Trong đó, $\mu$ là giá trị trung bình và $\sigma$ là độ lệch chuẩn của tổng thể. Tiếp theo, họ kết hợp hai biến số để tạo ra một chỉ số đặc trưng hoàn toàn mới phản ánh mức độ an toàn tài chính (ví dụ tỷ lệ nợ trên thu nhập). Việc trích xuất đặc trưng (Feature Engineering) này làm tăng độ chính xác của mô hình lên gấp nhiều lần so với việc để AutoML tự mò mẫm trên dữ liệu thô ban đầu.
Lúc này, nhà phân tích phải áp dụng kỹ thuật hiệu chỉnh L1 (Lasso Regression) hoặc L2 (Ridge Regression) bằng cách cộng thêm một lượng phạt vào hàm mất mát (Loss Function):
AutoML hoàn toàn không có năng lực thiết lập và đánh giá các bài thử nghiệm này. Data Scientist phải trực tiếp sử dụng kiểm định giả thuyết thống kê để đưa ra kết luận:
Đối với những ai đang tìm kiếm một lộ trình bài bản để xây dựng nền tảng tư duy toán thống kê kết hợp lập trình thuật toán thực chiến nhất nhằm thích nghi với bối cảnh công nghệ mới, việc đầu tư nghiêm túc vào các chương trình khóa học Data Science chuẩn mực chính là chiếc chìa khóa vạn năng mở ra nấc thang thăng tiến cao nhất trong sự nghiệp dữ liệu.
#DataScience #AutoML #ToanThongKe #StatisticalThinking
Thực tế lại chứng minh điều hoàn toàn ngược lại. Khi rào cản kỹ thuật về lập trình được hạ thấp bởi các công cụ kéo thả tự động, sự phân cấp năng lực giữa các kỹ sư dữ liệu không nằm ở tốc độ gõ code mà nằm ở độ sâu của Tư duy Thống kê.
1. Bản Chất Của "Bẫy Hộp Đen" Trong AutoML
AutoML là một giải pháp tuyệt vời để tự động hóa các tác vụ tính toán lặp đi lặp lại. Nó có thể huấn luyện đồng thời hàng trăm mô hình từ Hồi quy tuyến tính, Rừng ngẫu nhiên (Random Forest) đến các mạng nơ-ron phức tạp để tìm ra hệ số xác định $R^2$ hay độ chính xác (Accuracy) cao nhất trên tập dữ liệu thử nghiệm.Tuy nhiên, thuật toán AutoML vận hành thuần túy dựa trên các phép toán số học mà không hề hiểu về ngữ cảnh và bản chất của dữ liệu. Điều này dẫn đến những thảm họa về mặt mô hình hóa mà chỉ có tư duy thống kê của con người mới có thể phát hiện:
Hiện tượng Quá khớp (Overfitting) và Rò rỉ dữ liệu (Data Leakage)
AutoML rất dễ bị đánh lừa bởi hiện tượng rò rỉ thông tin từ tập kiểm thử sang tập huấn luyện. Một mô hình có sai số huấn luyện cực nhỏ gần như bằng $0$ nhưng khi đưa vào môi trường Production thực tế lại đưa ra các dự báo sai lệch hoàn toàn.Tư duy thống kê giúp nhà phân tích hiểu rõ bản chất của mối quan hệ đánh đổi giữa Bias và Variance thông qua phương trình sai số tổng quát:
Trong đó, $\sigma^2$ là sai số ngẫu nhiên không thể giảm thiểu của dữ liệu. Việc mù quáng tối ưu hóa thuật toán bằng công cụ tự động mà không hiểu cơ chế phân phối xác suất kiểm thử sẽ chỉ làm tăng hệ số Variance và khiến mô hình mất đi khả năng tổng quát hóa (generalization).
Bài toán Đa cộng tuyến (Multicollinearity)
Khi hai hay nhiều biến độc lập trong mô hình hồi quy có mối quan hệ tuyến tính mạnh với nhau, hệ số ước lượng của thuật toán sẽ bị sai lệch nghiêm trọng. AutoML hoàn toàn bỏ qua điều này, dẫn đến việc giải thích mô hình bị đảo lộn (ví dụ: biến đáng lẽ mang tác động tích cực lại nhận hệ số hồi quy âm). Chỉ có nhà khoa học dữ liệu hiểu rõ phương pháp phân tích nhân tố VIF (Variance Inflation Factor) mới có thể loại bỏ nhiễu hệ thống này trước khi đưa dữ liệu vào huấn luyện.2. Feature Engineering – Nghệ Thuật Số Hóa Ngữ Cảnh Doanh Nghiệp
Một thuật toán máy học dù tiên tiến đến đâu cũng hoạt động dựa trên nguyên lý bất biến: "Garbage In, Garbage Out" (Dữ liệu đầu vào là rác thì kết quả trả ra cũng là rác). AutoML không thể tự động sáng tạo ra các đặc trưng dữ liệu mang tính chiến lược nếu không có sự can thiệp của tư duy thống kê và sự am hiểu nghiệp vụ.Hãy lấy ví dụ về bài toán chấm điểm tín dụng trong ngân hàng. Dữ liệu thô chỉ bao gồm thông tin: Số dư tài khoản hiện tại và Lịch sử thu nhập hằng tháng. AutoML sẽ chỉ trực tiếp đưa hai biến số này vào mô hình.
Nhưng một Data Scientist thực thụ sẽ sử dụng toán thống kê để chuẩn hóa dữ liệu theo phân phối chuẩn:
Trong đó, $\mu$ là giá trị trung bình và $\sigma$ là độ lệch chuẩn của tổng thể. Tiếp theo, họ kết hợp hai biến số để tạo ra một chỉ số đặc trưng hoàn toàn mới phản ánh mức độ an toàn tài chính (ví dụ tỷ lệ nợ trên thu nhập). Việc trích xuất đặc trưng (Feature Engineering) này làm tăng độ chính xác của mô hình lên gấp nhiều lần so với việc để AutoML tự mò mẫm trên dữ liệu thô ban đầu.
3. Regularization – Khi Toán Học Ngăn Chặn Sự Phình To Của Mô Hình
Để kiểm soát sự phức tạp của các mô hình dự báo lớn, việc hiểu sâu sắc các kỹ thuật kiểm soát trọng số (Regularization) là bắt buộc. Khi số lượng đặc trưng tăng lên, mô hình hồi quy thông thường sẽ có xu hướng quá khớp.Lúc này, nhà phân tích phải áp dụng kỹ thuật hiệu chỉnh L1 (Lasso Regression) hoặc L2 (Ridge Regression) bằng cách cộng thêm một lượng phạt vào hàm mất mát (Loss Function):
Hệ số $\lambda$ điều khiển mức độ phạt. Lasso ($\text{L1}$) có khả năng triệt tiêu hoàn toàn các hệ số hồi quy của các biến không quan trọng về mức $0$, giúp chọn lọc đặc trưng tự động một cách tối ưu. Hiểu rõ cơ chế toán học này giúp nhà phân tích chủ động tinh chỉnh mô hình thay vì phó mặc cho các vòng lặp tự động của máy tính.4. Tầm Quan Trọng Của Việc Kiểm Định Giả Thuyết (Hypothesis Testing)
Trong kinh doanh thực tế, mọi sự thay đổi trên hệ thống (ví dụ thay đổi giao diện website, thay đổi chính sách giá) đều cần được chứng minh tính hiệu quả một cách khoa học trước khi triển khai quy mô lớn thông qua thử nghiệm A/B (A/B Testing).AutoML hoàn toàn không có năng lực thiết lập và đánh giá các bài thử nghiệm này. Data Scientist phải trực tiếp sử dụng kiểm định giả thuyết thống kê để đưa ra kết luận:
- Thiết lập giả thuyết Không ($H_0$): Sự thay đổi không mang lại sự khác biệt về doanh thu.
- Thiết lập giả thuyết Đối ($H_1$): Sự thay đổi mang lại sự khác biệt thực sự có ý nghĩa thống kê.
- Sử dụng kiểm định t-test hoặc z-test để tính toán giá trị p-value. Nếu p-value $< 0.05$, doanh nghiệp mới có đủ cơ sở khoa học để bác bỏ giả thuyết $H_0$ và tiến hành thay đổi hệ thống.
5. Kết Luận
Công cụ AutoML hay các trợ lý trí tuệ nhân tạo chỉ giúp giải phóng chúng ta khỏi những tác vụ lặp đi lặp lại mệt mỏi. Chúng là những trợ lý xuất sắc nhưng không thể thay thế được vai trò của một "Kiến trúc sư trưởng" dữ liệu. Tương lai của ngành khoa học dữ liệu thuộc về những người biết cách kết hợp sức mạnh tính toán của máy tính với chiều sâu tư duy của toán học và thống kê ứng dụng.Đối với những ai đang tìm kiếm một lộ trình bài bản để xây dựng nền tảng tư duy toán thống kê kết hợp lập trình thuật toán thực chiến nhất nhằm thích nghi với bối cảnh công nghệ mới, việc đầu tư nghiêm túc vào các chương trình khóa học Data Science chuẩn mực chính là chiếc chìa khóa vạn năng mở ra nấc thang thăng tiến cao nhất trong sự nghiệp dữ liệu.
#DataScience #AutoML #ToanThongKe #StatisticalThinking